1. 初始化环境
1.1. 安装 pika
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # 下载软件包
PIKA_VERSION="$(wget -qO- https://api.github.com/repos/Qihoo360/pika/releases/latest | grep 'tag_name' | cut -d\" -f4)"
wget -q https://github.com/Qihoo360/pika/releases/download/${PIKA_VERSION}/pika-linux-x86_64-${PIKA_VERSION}.tar.bz2
# 解压软件包
tar xjf pika-linux-x86_64-${PIKA_VERSION}.tar.bz2
# 建立程序目录
mkdir -p /usr/local/pika
# 拷贝 pika 应用程序到程序目录
\cp -arf output/* /usr/local/pika
# 清理安装文件
rm -rf output pika-linux-x86_64-${PIKA_VERSION}.tar.bz2*
|
1.2. 建立目录结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # 建立数据目录
mkdir -p /data/pika/db
# 建立同步目录
mkdir -p /data/pika/dbsync
# 建立备份目录
mkdir -p /data/pika/dump
# 建立日志目录
mkdir -p /data/pika/log
# 建立配置文件
touch /data/pika/pika.conf
# 设置权限
chown -R worker.worker /data/pika
|
2. 配置和启动
2.1. 建立配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
| cat > /data/pika/pika.conf <<EOF
# Pika 端口
port : 9231
# Pika 进程数量,不建议超过核心数量,Pika 是多线程的
thread-num : 6
# Sync 线程数量
sync-thread-num : 6
# Sync 处理线程的任务队列大小,一般没有必要修改
sync-buffer-size : 10
# Pika 日志目录
log-path : /data/pika/log/
# Pika 的 log 级别(INFO|ERROR),任何一个级别均记录慢日志
loglevel : ERROR
# Pika 数据目录
db-path : /data/pika/db
# Pika 底层引擎的 write_buffer_size 配置
# 大会快,但越大刷盘越久,需要权衡
write-buffer-size : 268435456
# Pika 的连接超时时间,就是连接 sleep 多久了就把它断开
timeout : 3600
# 密码管理员密码,默认为空
requirepass :
# 主从同步密码,默认为空
masterauth :
# 用户密码,默认为空
userpass :
# 指令黑名单,普通用户将不能使用黑名单中的指令
# 指令之间使用 “,” 隔开,默认为空
userblacklist :
# Pika 的 dump 文件名称前缀
dump-prefix :
# 守护进程模式(yes|no)
daemonize : no
# 支持 migrate slot,作为 codis 节点时需开启(yes|no)
slotmigrate : no
# Pika 的 dump 目录
dump-path : /data/pika/dump/
# Pika 的 dump 文件过期时间,默认为 0,不过期
dump-expire : 0
# Path 的 pid 文件路径
pidfile : /data/pika/pika.pid
# 最大连接数
maxclients : 8192
# sstable 文件大小,默认是 20M
# 文件越小,速度越快,合并代价越低,但文件数量就会非常多
# 文件越大,速度相对变慢,合并代价大,但文件数量会很少
target-file-size-base : 20971520
# binlog 文件保留时间,最小为 1
expire-logs-days : 7
# binlog 文件最大数量,最小为 10
# 超过设定数量就开始自动清理,始终最多保留设定数量个文件
expire-logs-nums : 100
# root 用户连接保证数量
# Pika 达到最大连接数时,也能确保本地有指定个连接可以登入 Pika
root-connection-num : 2
# 慢日志记录时间,单位为微秒
slowlog-log-slower-than : 10000
# 作为从服务器时,是否为只读状态(yes|no,1|0)
slave-read-only : 0
# Pika 数据同步目录
db-sync-path : /data/pika/dbsync/
# 主从数据同步传输速度上限
# 最大值 125MB,最小值 0,如果设置的值超出范围会被校准为最大值
db-sync-speed : 60
# 指定监听的网卡
# network-interface : eth0
# 启用主从复制,并作为从服务器从指定服务器同步数据
# slaveof : master-ip:master-port
# 定时任务,格式 start-end/ratio
# 例如 02-04/60,Pika 将在每天 2 ~ 4 点检查磁盘使用量,如果超过 60% 则开始数据整理
# 当 compact-interval 被设置时,compact-cron 将会被自动禁用
# compact-cron : 20-24/60
# 整理间隔,格式 interval/ratio
# 例如 6/60,Pika 将每隔 6 小时检查磁盘使用量,如果超过 60% 则开始数据整理
# compact-interval 的优先级高于 compact-cron
# compact-interval :
###################
## 关键设置 ##
###################
# binlog 文件大小,默认为 100MB,启动后不可修改,范围为 [1K, 2G]
binlog-file-size : 104857600
# 压缩方式,默认为 snappy,启动后不可修改(snappy|none)
compression : snappy
# 后台 flush 线程数量,默认为1,范围为 [1, 4]
max-background-flushes : 2
# 指定后台压缩线程数量,默认为1,范围为[1, 8]
max-background-compactions : 4
# 缓存文件数量上限,默认为 5000
max-cache-files : 5000
# sstable 中 Level N+1 的最大容量是 Level N 的多少倍
# 默认为 10,可以设置为 5
max-bytes-for-level-multiplier : 10
EOF
|
2.2. 优化配置文件
thread-num
根据 CPU 核心数量设置,如果是 Pika 独占服务器,可以设置为 CPU 核心数量的 1.5 倍;
daemonize
如果直接以命令行模式启动,守护进程模式需要开启;
如果是托管到 systemd,则需要关闭守护进程模式;
slotmigrate
Pika 作为 codis 的数据节点时,需要开启 slotmigrate 模式以支持 migrate slot;
expire-logs-nums
Pika 的主从同步和 Redis 类似,首次需要 dump 主服务器完整数据,并同步到从服务器,之后的数据同步通过同步 binlog 来进行;
首次同步时,将完整数据传输到从服务器上会比较慢,需要设置更大的 expire-logs-nums 值,避免数据同步过慢,同步完成时起始 binlog 已被删除;
db-sync-speed
首次主从同步时,同步完整数据的速度上限,根据服务器配置进行设置;
由于数据同步使用的是 rsync,会占用大量资源和带宽,需要谨慎设置;
compact-cron
compact-cron 和 compact-interval 更建议使用 compact-cron;
由于数据整理将会占用大量系统资源,Pika 在整理时的 Qps 很低;
使用 compact-cron 可以设置在低峰时间进行检查和整理;
2.3. 建立服务
2.3.1 配置服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| cat > /usr/lib/systemd/system/pika.service <<EOF
[Unit]
Description=pika server
[Service]
WorkingDirectory=/data/pika/
ExecStart=/usr/local/pika/bin/pika -c /data/pika/pika.conf
Restart=always
User=worker
Group=worker
[Install]
WantedBy=multi-user.target
EOF
|
2.3.2 激活服务
1
2
3
4
5
| # reload service
systemctl daemon-reload
# enable service,auto start service after system boot
systemctl enable pika.service
|
2.3.3 管理服务
1
2
3
4
5
6
7
8
9
10
11
| # start service
systemctl start pika
# stop service
systemctl stop pika
# restart service
systemctl restart pika
# show service status
systemctl status pika
|
3. 主从同步
通过上面的步骤,配置两个 Pika 实例;
3.1. 清理从服务器数据
从服务器如果已经有数据,需要先进行数据清理;
1
2
3
4
5
6
7
8
9
10
| # run on slave
# stop service
systemctl stop pika
# clean data
rm -rf /data/pika/*/*
# start service
systemctl start pika
|
3.2. 自动同步
3.2.1. 通过配置文件
修改从服务器 Pika 配置文件,并重启 Pika 服务,主从同步自动开始;
1
2
| # option in pika config file
slaveof : 172.20.2.1:9231
|
3.2.2. 使用命令
Pika 服务启动时,本地使用指令启动同步;
1
2
| # run on slave
redis-cli -p 9231 slaveof 172.20.2.1 9231
|
3.3. 手动同步
在 pika 2.3.3 之前的版本,自动主从同步存在 rsync 全同步过程反复重传的问题,此时配置文件中设置的同步速率上限会失效,使用 125 MB/s 的满速率传输;
对于配置较差的机器,容易将主服务器的带宽和 CPU 占满,影响主服务器的对外服务;
对于低版本的 pika,可使用手动同步方案确保同步成功,且占用的资源是可控的;
3.3.1. 准备主服务器数据
1
2
3
4
5
6
7
| # run on master
# dump master data
redis-cli -p 9231 bgsave
# set master keep more binlog
redis-cli -p 9231 config set expire-logs-nums 300
|
3.3.2. 在从服务器建立同步服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| # run on slave
# stop service
systemctl stop pika
# create sync directory
mkdir -p /data/pika/sync
# create rsync config file
cat > /data/pika/sync/rsync.conf <<EOF
uid = worker
gid = worker
use chroot = no
log file = /data/pika/sync/rsyncd.log
pid file = /data/pika/sync/rsyncd.pid
lock file = /data/pika/sync/rsync.lock
[pika]
uid = worker
gid = worker
path = /data/pika/db
comment = pika db files
ignore errors = yes
read only = no
list = no
auth users = pika
secrets file = /data/pika/sync/rsyncd.secrets
EOF
# create rsync secrets file
cat > /data/pika/sync/rsyncd.secrets <<EOF
pika:pika
EOF
chmod 600 /data/pika/sync/rsyncd.secrets
# start rsync service
rsync --daemon --config=/data/pika/sync/rsync.conf --address=<slave_ip> --port=12231
|
3.3.3. 同步主从数据
1
2
| # run on master
rsync -avP --bwlimit=409600 --port=12231 /data/pika/dump/<today_date>/* pika@<slave_ip>::pika
|
3.3.4. 启动主从同步
从服务器 /data/pika/db/info 文件的最后两行分别是 start_binlog_name 和 start_binlog_pos;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # run on slave
# stop rsync service
kill `ps ax | grep rsync | grep 12231 | awk '{print $1}'`
# clean sync files
rm -rf /data/pika/sync
# delete sync info file
rm -f /data/pika/db/info
# start service
systemctl start pika
# start sync with assign binlog file and pos
redis-cli -p 9231 slaveof <master_ip> <master_port> <start_binlog_name> <start_binlog_pos>
|
3.3.5. 确认主从同步状态
binlog_offset 的第一个字段是 binlog_name;
主从实例 binlog_offset 相同则代表 binlog 已同步;
1
2
| # run on master and slave
redis-cli -p 9231 info log
|
3.3.6. 清理主服务器数据
1
2
3
4
| # run on master
# clean dump files
redis-cli -p 9231 delbackup
|
4. 水平扩展
4.1. codis + pika
4.1.1. 优点
- 直接将 pika 作为 codis 数据节点,配置简单;
- 通过 codis fe 可线上扩容、增删节点、移动数据,调整时基本不影响服务;
- 通过 codis fe 故障时可迅速切换主从,实现高可用;
4.1.2. 缺点
- codis 官方并不兼容 pika,pika 的兼容方案由开源社区贡献,出现时间短不成熟;
- pika 的应用场景与 redis 不同,数据量大得多,速度也慢得多,动态管理是否能很好的稳定工作有很多不确定性;
- 启用 slot 支持后,pika 的数据结构会发生改变,对已存在的数据,需要进行逐条迁移,如果数据量大会需要很长时间;
4.1.3. 实现步骤
- 开启 pika 配置文件中的 slotmigrate 选项;
- 将 codis 集群中的 codis server 替换成 pika;
4.2. twemproxy + pika
4.2.1. 优点
- twemproxy 作为久经考验的方案,非常稳定;
- twemproxy 配置非常简单,pika 也无需进行任何调整;
- 扩容方案操作简单,倍数扩容,将从服务器断开主从加入集群即可;
4.2.2. 缺点
- twemproxy 不支持优雅重启,修改配置需要重启,连接会闪断;
- 每次扩容只能倍数扩容,不够灵活,扩容后一定时期内会闲置和浪费资源;
- 扩容后 pika 上会有 50% 的冗余数据,需要手动清理;
- 节点故障时,需要手动进行主从切换,故障恢复需要一定时间;
4.2.3. 实现步骤
4.2.3.1 迁移现有架构
现有的单组 pika 主从架构迁入基于 twemproxy 的水平扩展架构非常简单,只需要两步:
- 将现有 pika 实例加入 twemproxy 配置中;
1
2
3
4
5
6
7
8
9
10
11
12
13
| pooling-pika-message-socket:
listen: /usr/local/nutcracker/run/pika.sock 0777
hash: fnv1a_64
distribution: modula
redis: true
timeout: 1000
backlog: 2048
preconnect: false
auto_eject_hosts: false
server_retry_timeout: 2000
server_failure_limit: 1
servers:
- pika01.may.ac.cn:9231:1
|
- 将程序中的连接配置从直连 pika 改为连接 twemproxy;
数据上无需做任何处理,调整完毕立即可用;
4.2.3.2 水平扩展原理
基于 twemproxy 的水平扩展策略的原理,主要建立在以下几个事实之上:
- twemproxy 使用设定的 hash 算法将键散列到 servers 列表中的某个实例;
- twemproxy 会对 servers 中的实例按名字或地址的自然序进行排序;
- 从服务器保有主服务器的全部数据;
所以在我们能够确定散列时使用的实例顺序时,我们也能够保证之前主实例承担的键,会由主和新加入的从共同承担,并且不会丢失数据;
4.2.3.3 水平扩展步骤
基于 twemproxy 的水平扩展策略,主要是三个步骤:
- 将从实例解除主从同步,变为主实例;
- 修改 twemproxy 配置,将新的主实例加入服务节点群组,并重启;
- 为所有的主实例增加从实例;
下面我们针对现实的情况,举一个实例;
| 实例 | 角色 | 主实例 | 键散列值 |
|---|
| pika01.may.ac.cn | master | none | 0 |
| pika02.may.ac.cn | slave | pika01.may.ac.cn | 0 |
| 实例 | 角色 | 主实例 | 键散列值 |
|---|
| pika01.may.ac.cn | master | none | 0 |
| pika02.may.ac.cn | master | none | 1 |
| pika03.may.ac.cn | slave | pika01.may.ac.cn | 0 |
| pika04.may.ac.cn | slave | pika02.may.ac.cn | 1 |
| 实例 | 角色 | 主实例 | 键散列值 |
|---|
| pika01.may.ac.cn | master | none | 0 |
| pika02.may.ac.cn | master | none | 1 |
| pika03.may.ac.cn | master | none | 2 |
| pika04.may.ac.cn | master | none | 3 |
| pika05.may.ac.cn | slave | pika01.may.ac.cn | 0 |
| pika06.may.ac.cn | slave | pika02.may.ac.cn | 1 |
| pika07.may.ac.cn | slave | pika03.may.ac.cn | 2 |
| pika08.may.ac.cn | slave | pika04.may.ac.cn | 3 |
4.2.3.4 冗余数据清理
扩容后,由原主从实例平摊了原主实例承担的键;
所以扩容后的所有实例,都有 50% 的数据是冗余的;
如果数据被写入时是具有有效期的,那么等待数据自然过期即可;
但如果数据并未设置有效期,那么就需要手工清理;
冗余数据清理的基础思路,是使用与 twemproxy 相同的散列算法,遍历实例上的每个键,并将不属于实例的键删除;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
| #!/usr/bin/php
<?php
set_time_limit(0);
ini_set('default_socket_timeout', 300);
/**
* 冗余键清理器
*/
class Cleaner {
/**
* 每次扫描的数量
*/
const BATCH_NUM = 100;
/**
* 每批处理的休息时间(ms)
*/
const REST_TIME = 10;
/**
* 重试间隔时间(ms)
*/
const RETRY_TIME = 3000;
/**
* 重试次数
*/
const RETRY_TIMES = 10;
/**
* 哈希算法
*/
const HASH_ALGO = 'fnv1a64';
/**
* Redis 主机地址
*
* @var string
*/
private $host;
/**
* Redis 端口
*
* @var integer
*/
private $port;
/**
* 服务器 Hash 模
*
* @var integer
*/
private $modula;
/**
* 服务器 Hash 索引
*
* @var integer
*/
private $index;
/**
* Redis实例
*
* @var \Redis
*/
private $redis = NULL;
/**
* 初始化清理器
*
* @param string $host
* @param int $port
* @param int $modula
* @param int $index
*/
public function __construct($host, $port, $modula, $index) {
$this->host = $host;
$this->port = $port;
$this->index = $index;
$this->modula = $modula;
}
/**
* 获取键的哈希索引
*
* @param string $key
* @return int
*/
public function getKeyIndex($key) {
return hexdec(substr(hash(self::HASH_ALGO, $key), -8)) % $this->modula;
}
/**
* 执行扫描
*
* @param int $iterator
* @param string $pattern
* @param int $count
* @return array|bool
* @throws Exception
*/
public function scan(&$iterator, $pattern = null, $count = 0) {
for ($i = 0; $i < self::RETRY_TIMES; $i++) {
try {
if (empty($this->redis)) {
$this->redis = new Redis();
$this->redis->connect($this->host, $this->port);
}
return $this->redis->scan($iterator, $pattern, $count);
} catch (Exception $e) {
$this->redis = NULL;
print_r($e);
usleep(self::RETRY_TIME * 1000);
}
}
throw new Exception("Too many retry times!");
}
/**
* 执行查询
*
* @param string $command
* @param array ...$params
* @return mixed
* @throws Exception
*/
public function exec($command, ...$params) {
for ($i = 0; $i < self::RETRY_TIMES; $i++) {
try {
if (empty($this->redis)) {
$this->redis = new Redis();
$this->redis->connect($this->host, $this->port);
}
return $this->redis->$command(...$params);
} catch (Exception $e) {
$this->redis = NULL;
print_r($e);
usleep(self::RETRY_TIME * 1000);
}
}
throw new Exception("Too many retry times!");
}
/**
* 开始清理
*/
public function start() {
$cursor = NULL;
do {
$keys = $this->scan($cursor, '*', self::BATCH_NUM);
if (!empty($keys)) {
$delKeys = [];
foreach ($keys as $key) {
if ($this->getKeyIndex($key) != $this->index) {
$delKeys[] = $key;
}
}
if (count($delKeys) > 0) {
echo implode("\n", $delKeys) . "\n";
$this->exec('del', $delKeys);
}
}
}
while ($cursor > 0);
}
}
if (count($argv) < 5) {
echo "Error params!\n";
echo "eg: ./keyCleaner 127.0.0.1 6379 4 1\n";
exit(1);
}
list($script, $host, $port, $modula, $index) = $argv;
$cleaner = new Cleaner($host, $port, $modula, $index);
$cleaner->start();
|
在水平扩展完成后,执行以下命令即可:
1
| ./keyCleaner host port total_node_num node_index
|
total_node_num 是服务节点数量;
node_index 是当前节点在排序中的索引位置;
由于遍历所有的键将需要很长时间,建议将命令挂载到后台执行;
4.2.3.5 注意事项
- twemproxy 会对 servers 中的实例按名字或地址的自然序进行排序;
要清楚和明确这个规则,否则可能会导致键扩容后不能分到正确的实例;
1
2
3
4
| servers:
- pika01.may.ac.cn:9231:1
- pika02.may.ac.cn:9231:1
- pika03.may.ac.cn:9231:1
|
1
2
3
4
| servers:
- pika01.may.ac.cn:9231:1
- pika03.may.ac.cn:9231:1
- pika02.may.ac.cn:9231:1
|
以上两个配置,实际效果并不会有区别,散列时会使用前者的顺序;
所以,当地址的自然序不符合要求时,需要指定名字校对排序;
1
2
3
4
| servers:
- pika01.may.ac.cn:9231:1 server01
- pika03.may.ac.cn:9231:1 server02
- pika02.may.ac.cn:9231:1 server03
|
增加名字后,散列时会优先按照名字的自然序排序;
- twemproxy 配置中 distribution 设置为 modula,更容易预估键散列结果;
对键名 hash 并取模,是一个清晰和可预期的算法;
使用取模算法,才能够保证水平扩展后,加入群组的从实例能够正确平摊原主实例承担的键;
- twemproxy 配置中 auto_eject_hosts 应禁用,所有节点的 weight 应相同;
auto_eject_hosts 启用时,如果服务器连接不上,将会被踢出群组,服务器恢复时会再次加入群组;
对于可丢失的缓存来说,这样做并没有问题,但对于持久化数据的水平扩展架构,这将是灾难性的;
服务器被踢出群组,将使键的散列结果发生变化,踢出前后的键分配将不固定,所以必须禁用;
而节点的 weight 也是影响键散列结果的重要因素,weight 高的节点将承担更多的键;
虽然通过计算,我们也能够保证水平扩展后的结果,但强烈建议所有的节点使用同样的权重,这样结果将是简单和可预期的;
5. 日常管理
5.1. 管理指令
client kill all
踢掉所有已连接的客户端
bgsave
异步 dump 完整的数据库到 dump 目录;
备份目录名是配置文件中设定的前缀加上当前日期;
备份目录中的 info 文件记录备份截止的 binlog 文件名和 position 信息,便于主从同步使用;
info keyspace
查看或扫描数据库中每类键的数量信息;
pika 默认并不实时记录键的数量信息,需要用 info keyspace 1 指令开始扫描;
待后台扫描执行完毕,可以使用 info keyspace 0 或 info keyspace 查看扫描的信息;
config get/set
使用 config get * 或 config get option 可以查看全部或指定设置选项当前的值;
使用 config set option value 可以设置指定设置选项的值,即时生效,无需重启;
config set 支持的选项有限,使用 config set * 可以查看可以设置的选项列表;
pika 重启时会从配置文件读取配置,所以 config set 修改的选项会失效;
调用 config set 命令动态更新配置后最好同步修改配置文件;
compact
pika 底层存储引擎是基于 rocksdb 改造,存在空间占用放大问题,除了自动 compaction,也可以手动执行 compact 命令,强制执行数据压缩;
数据压缩执行完占用空间会明显减小,但耗时较长,压缩过程中 pika 性能会大幅下降,建议低峰期执行;
readonly
开启或关闭服务器只读状态,readonly on|off 或 readonly 1|0;
delbackup
删除 dump 目录中除了主从同步正在使用的备份以外的所有备份;
slaveof
通过 slaveof 命令可以开启或关闭主从同步;
使用 slaveof no one 可以立即关闭已经建立的主从同步;
使用 slaveof master_ip master_port 可以立即开始与指定的主服务器进行主从同步;
使用 slaveof master_ip master_port start_binlog_name start_binlog_pos 可以在开始主从同步的同时指定 binlog 同步的开始位置;
5.2. 注意事项
pika 会读写大量文件,系统文件打开数限制需要设置的高一些;
systemd 默认文件打开数为 4096,不继承系统设置,需要在 /etc/systemd/system.conf 或 service 文件中强制指定;
1
2
3
4
5
| cat >> /etc/systemd/system.conf <<EOF
DefaultLimitCORE=infinity
DefaultLimitNOFILE=infinity
DefaultLimitNPROC=infinity
EOF
|
pika 的 SCAN 命令实现方式与 redis 不同;
pika 执行 SCAN 命令时,如未指定 COUNT 参数,将会列出所有的匹配项,会非常非常慢,并卡住所有线程,所以执行 SCAN 一定要指定一个较小的 COUNT;
pika 进行压缩整理时,会占用大量系统资源,并且占用的磁盘空间会膨胀;
pika 在 compact 时,磁盘空间会膨胀 50% ~ 100%,要注意是否有足够的空间进行整理;
pika 在整理时,需要占用大量的 CPU 和内存,数据如果很大,整理时间会非常长,可能会持续数小时,不要在高峰期整理;
pika 在整理时,QPS 会下降到原来的一半或者更低,需要确定是否会影响线上服务;
6. 监控
6.1. 日志
日志目录中有三个软链接,分别是:
pika.INFO
pika.ERROR
pika.FATAL
分别记录着 pika 三个等级的日志信息;
发生故障时可以从最严重的级别开始依次查看;
慢查询会同时被记录在 pika.INFO 和 pika.ERROR 里;
6.2. 数据监控
6.2.1. 使用命令查询
6.2.1.1. 查询命令
6.2.1.2. 结果示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| # Server
pika_version:2.2.6 ----------------------------- pika 版本信息
os:Linux 3.10.0-514.16.1.el7.x86_64 x86_64 ----- 操作系统信息
arch_bits:64 ----------------------------------- 操作系统位数
process_id:12226 ------------------------------- pika 进程 id
tcp_port:9231 ---------------------------------- pika 监听端口
thread_num:6 ----------------------------------- pika 线程数量
sync_thread_num:6 ------------------------------ pika 同步线程数量
uptime_in_seconds:92832 ------------------------ pika 运行时间(秒)
uptime_in_days:2 ------------------------------- pika 运行时间(天)
config_file:/data/pika/pika.conf --------------- pika 配置文件路径
# Data
db_size:167421439361 --------------------------- pika db 当前大小(byte)
db_size_human:159665M -------------------------- pika db 当前大小(自适应)
compression:snappy ----------------------------- pika 当前压缩方案
used_memory:2658139096 ------------------------- pika 占用的内存大小(byte)
used_memory_human:2534M ------------------------ pika 占用的内存大小(自适应)
db_memtable_usage:335232088 -------------------- pika memtable 用量
db_tablereader_usage:2322907008 ---------------- pika tablereader 用量
# Log
log_size:10601924353 --------------------------- pika log 当前大小(byte)
log_size_human:10110M -------------------------- pika log 当前大小(自适应)
safety_purge:write2file111795 ------------------ pika 当前能够安全清理的最新日志
expire_logs_days:7 ----------------------------- pika 日志过期时间
expire_logs_nums:100 --------------------------- pika 日志保留最大数量
binlog_offset:111805 28779269 ------------------ pika 当前的 binlog id 和位置
# Clients
connected_clients:1 ---------------------------- 当前连接数
# Stats
total_connections_received:1617 ---------------- 总连接次数统计
instantaneous_ops_per_sec:4679 ----------------- 当前 qps
total_commands_processed:354452092 ------------- 总执行命令次数统计
is_bgsaving:No, , 0 ---------------------------- pika 备份信息:是否在备份,备份名称
is_scaning_keyspace:No ------------------------- pika 是否在扫描 keyspace
is_compact:No ---------------------------------- pika 是否在执行数据压缩
# Replication(MASTER)
role:master ------------------------------------ pika 在主从同步中的角色(slave|master)
connected_slaves:1 ----------------------------- 连接的从实例数量
slave0: host_port=172.20.2.230:93 state=online - 连接到主服务器的从实例信息列表
# Replication(SLAVE)
role:slave ------------------------------------- pika 在主从同步中的角色(slave|master)
master_host:172.20.2.230 ----------------------- pika 主服务器地址
master_port:9231 ------------------------------- pika 主服务器端口
master_link_status:up -------------------------- 与主服务器的链接状态(up|down)
slave_read_only:1 ------------------------------ 从服务器是否只读(0|1)
# Keyspace ------------------------------------- key 数量展示,仅在执行 info keyspace 1 时更新
# Time:1970-01-01 08:00:00 --------------------- 上一次统计的时间
kv keys:0
hash keys:0
list keys:0
zset keys:0
set keys:0
|
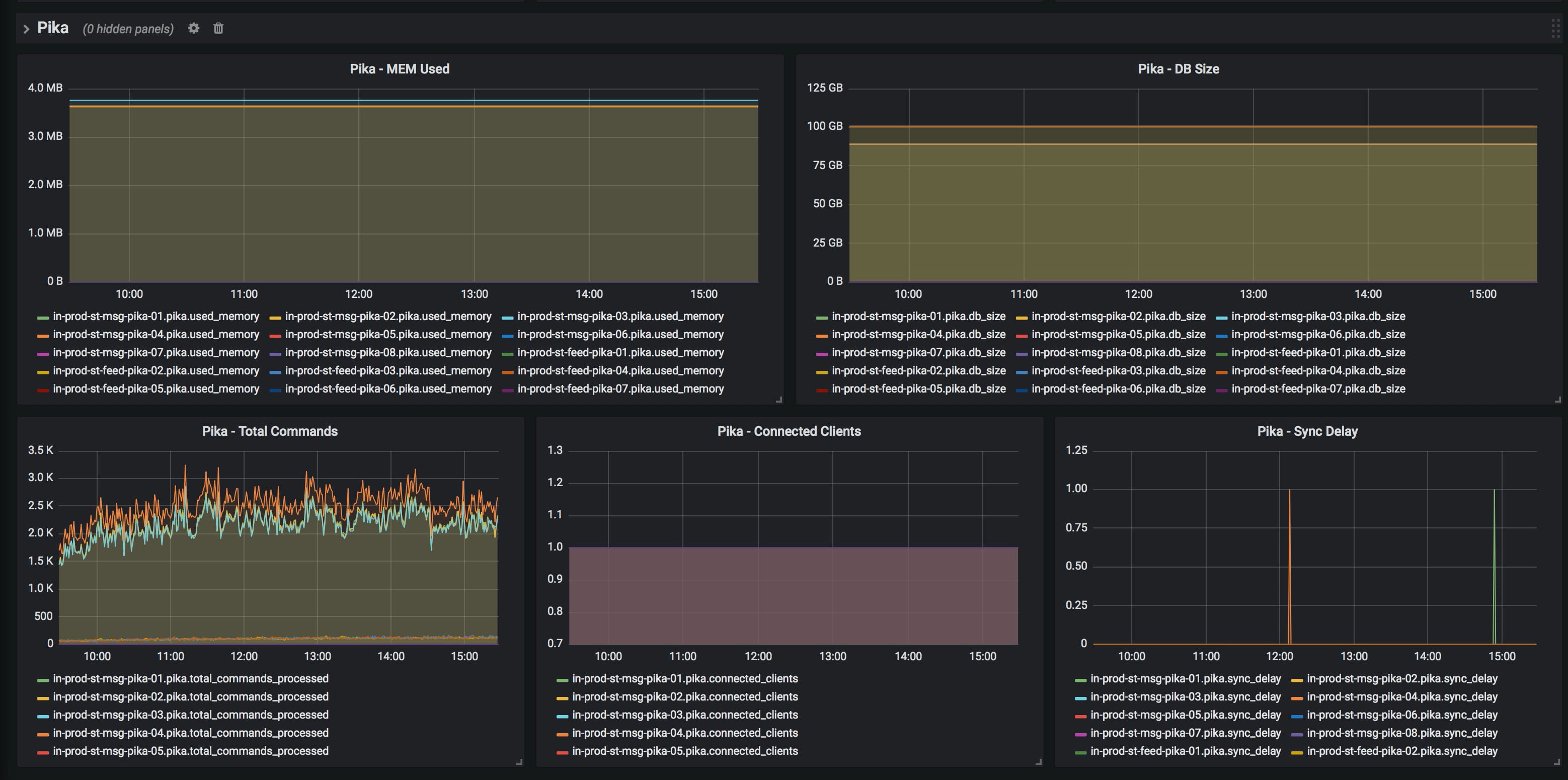
6.2.2. 使用脚本收集数据
CloudWatch 和 OpenFalcon 仅能收集到系统的性能指标,不能获取到 pika 服务本身的性能数据;
但我们借助本地运行 OpenFalcon 监控进程,可以通过定时运行脚本执行 info 命令获取数据,并将数据发送到 OpenFalcon 实现 pika 服务性能监控;
6.2.2.1 数据收集脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| # /home/worker/monitor/pika_monitor.py
import re
import commands
import time
import requests
import json
import socket
_stat_regex = re.compile(r'(\w+):([0-9]+\.?[0-9]*)\r')
def get_info(host, port):
command = 'redis-cli -h %s -p %s info' % (host, port)
info = commands.getoutput(command)
return dict(_stat_regex.findall(info))
def format_falcon_data(info_dict, endpoint, metric):
timestamp = int(time.time())
expected_keys = {
'db_size': 'GAUGE',
'connected_clients': 'GAUGE',
'used_memory': 'GAUGE',
'total_commands_processed': 'COUNTER'
}
event_list = []
for key, vtype in expected_keys.items():
if key not in info_dict:
continue
else:
try:
value = int(info_dict[key])
except:
continue
event_list.append({
'Metric': '%s.%s' % (metric, key),
'Endpoint': endpoint,
'Timestamp': timestamp,
'Step': 60,
'Value': value,
'CounterType': vtype,
})
return event_list
if __name__ == "__main__":
url: http://127.0.0.1:1988/v1/push"
host = '127.0.0.1'
port = 9231
endpoint = socket.gethostname()
info_dict = get_info(host, port)
event_list = format_falcon_data(info_dict, endpoint, "pika")
result = requests.post(url, data=json.dumps(event_list))
print "falcon result: %s" % result.content
|
6.2.2.2 定时任务收集
1
| * * * * * python /home/worker/monitor/pika_monitor.py >> /home/worker/monitor/pika_monitor.log
|